前言
随着Sora和kimi的大火, 视频模型和超长序列语言模型的实践不断被人们摆到更重要的位置, 这篇博客主要从需求和基本思路以及实践这几个方面来讲解一下序列并行相关的内容。
需求
从产品需求的角度看, 长序列是必然的需求。从语言模型看, 做超长文本检索以及摘要有确定的需求(例如平时看文献)。sora能够生成超长视频, 在使用vanilla attention的情况下, attention的序列长度将为(T, H, W), 也就是时长, 高度, 宽度三者的乘积增长, 序列长度比图像模型上一个量级, 这也一定会成为sora训练和推理的难题。尽管当前的flash attention的显存消耗能够被优化到线性增长的程度, 但是当序列长度足够长, 显存依然可能不够。
就此,
- 我们的问题被定义为: 如何让transformer支持超长序列的训练和推理
- 问题的核心: 来源于显存装不下超长序列带来的显存需求, 而非模型太大带来的显存溢出
- 可能方法: 优化显存或者使用多GPU并行计算分摊显存和计算
基本思路
首先我们需要将一句话铭记于心, 默念三遍:
transformer模型中, 序列的概念仅在attention这个操作中被需要, 在做MLP等其他操作时, 打乱序列甚至打乱batch都是可以的, 只要在attention操作时将序列顺序恢复即可。
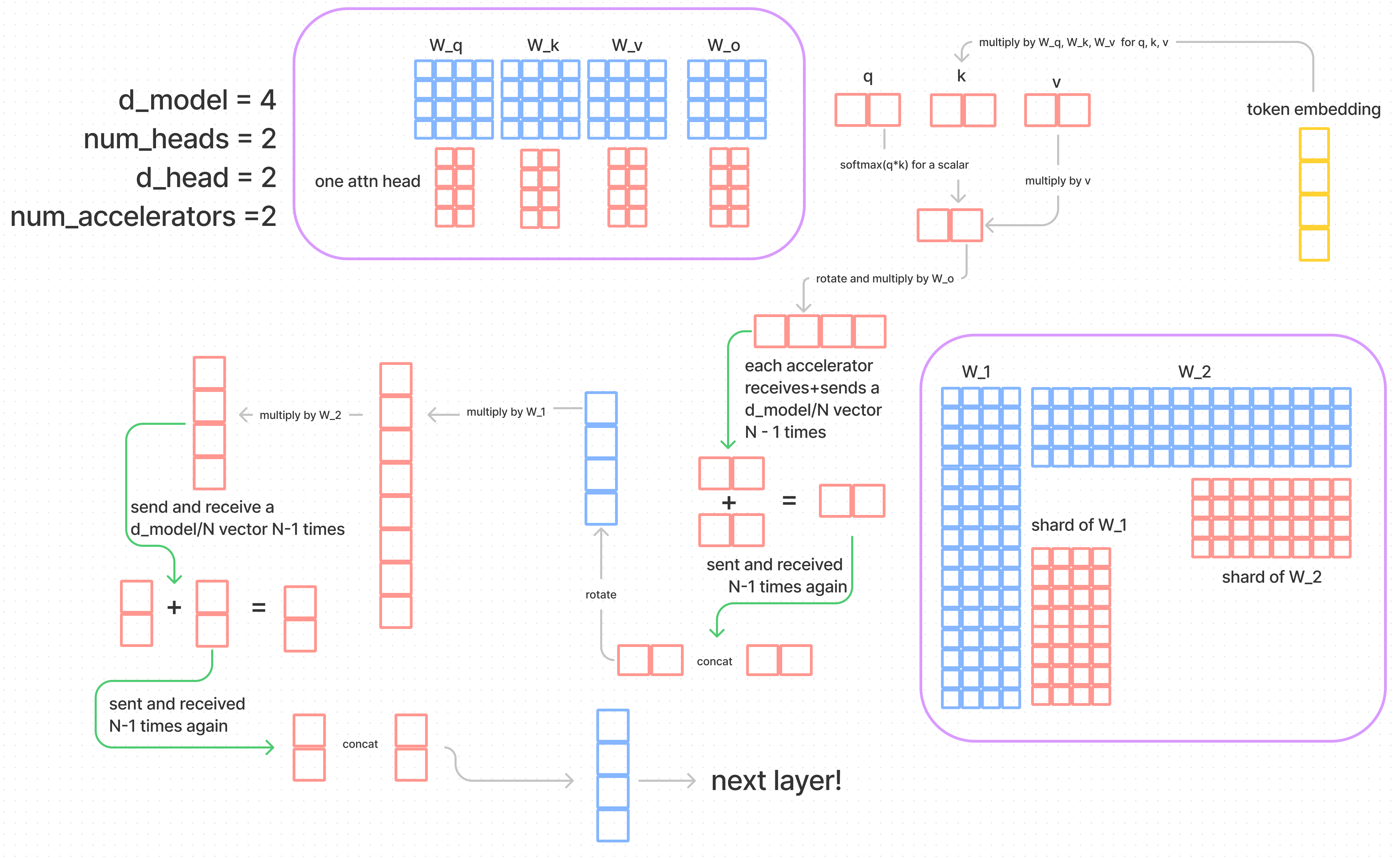
对于超长序列支持问题, 可能最直接的想法就是使用张量并行, 将模型切分, 对应的序列也在(B, L, D)的D维度被切分, 从而可以节省显存。
但是需要注意的是, 我们遇到的问题是来自于序列过长, 而模型并非过大, 特别是diffusion的模型都还非常小, 一张显卡放的下。其次, 使用模型并行中途计算需要的通信同步开销较大, 小模型做张量并行不值得。
再次回想我们铭记于心的话, 我们可以思考, 可否将序列(B, L, D) 在L维度切分, 在多张卡上做MLP等和序列无关的操作(无需通信), 在做attention时将相关的内容从其他GPU获取, 再进行attention操作, 再将计算结果同步到其他GPU上。这样比张量并行的好处在于无需切分模型, 减少通信量, 提高模型的吞吐与性能。
基本实现
接下来介绍几个实现了序列并行的库或者算法:
约定
- B: batch size
- L: seq len
- D: hidden dim
- A: attention head size
- Z: number of attention heads
- N: number of GPU
- Z x A = D
N个GPU上存储了(B, L/N, D)的序列, 给出在分布式情况下计算self attention的算法。
Ring self attention(RSA)
这样的方式是通过在query的L维度上切分进行分布式的attention的计算。通信的方式是通过进程之间换装传递K和V的分块然后得到最后的计算结果, 这样的算法不受到Z大小的限制, 对GPU的数量是可扩展的。
第一阶段-环状传递分块的K来得到attention map
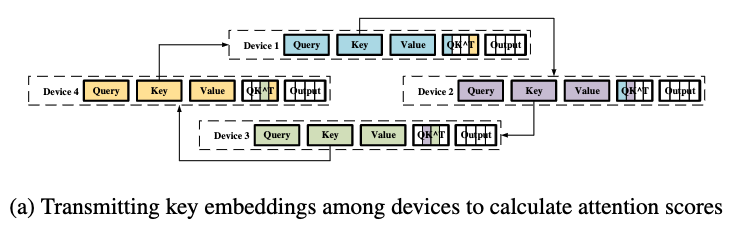
第二阶段-环状传递分块的V得到最后的结果
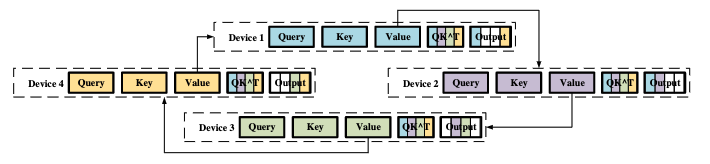
通俗的理解ring attention的机制, 其核心的并行的点在于, attention的计算是可以在query的sequence lens的维度上分块的, 也就是一部分的query和完整的key和value就可以得出此部分qeury对应的计算结果。而由于序列过长, key和value也被打散在不同进程中, 所以需要从其他进程不断传递并计算从而得到完整的key和value以得到最终结果。
不断集齐key和value这样的过程, 最简单的方式就是通过进程顺序点到点的方式完成, 显然这样的效率是不够高的, 在传递过程中如何尽量把各个节点之间的带宽利用好, 同时做好计算和通信的重叠, 而ring的方式就是系统领域典型的算法和方式, 能够做到较好的利用带宽, 在有良好的实线的情况下, 可以做到计算和通信的重叠。
Deepspeed ulyss
Attention的另外一种并行方式就是类似于张量并行的按照Attention head进行切分。也就是每个进程拥有完整的序列长度, 但是只有一部分的head个数, 这样同样能够节省显存, 而且这样的方法可以做到不改变Attention的实现, 也就是任何的attention算法都和Deepspeed ulyss兼容。但是缺点是并行的卡的数量不超过头的个数Z。
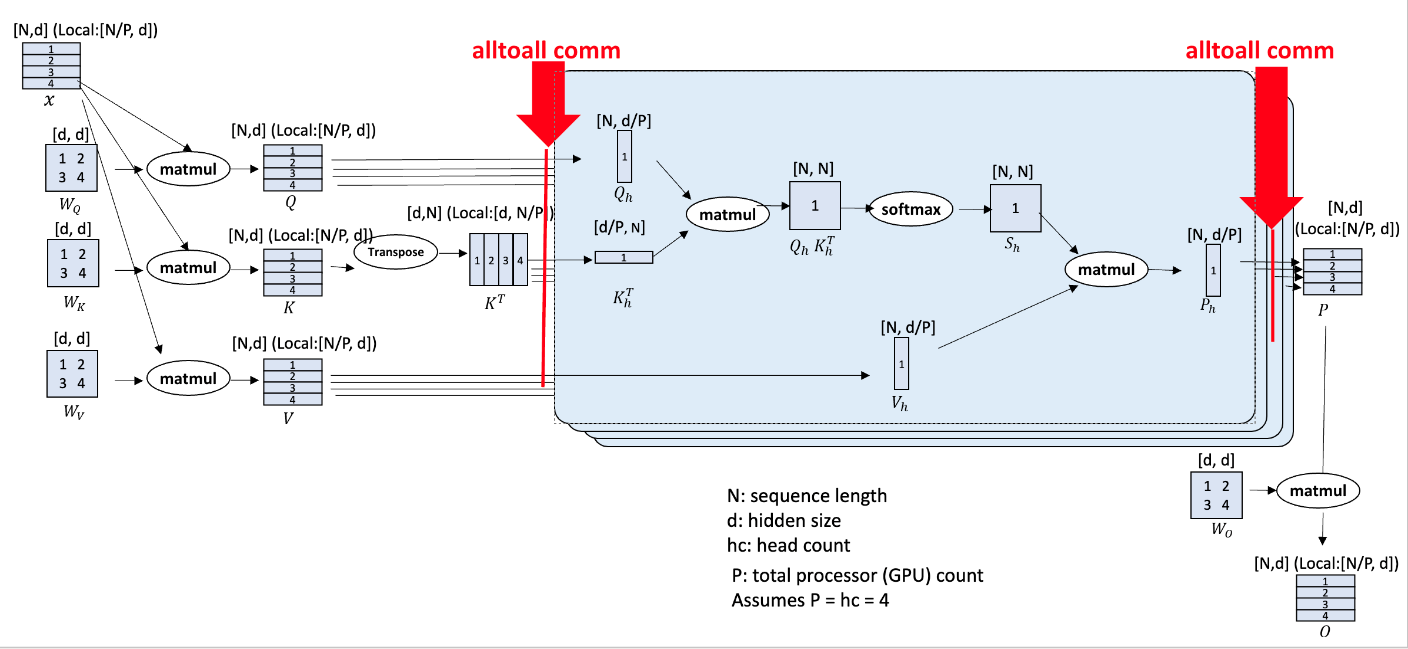
序列并行要求在MLP层无额外的操作, 所以每个进程中应该有部分的序列, 但是包含完整的attention head, 在进行attention并行时, 又要求每个进程需要完整的序列且是部分的头。所以可以遇见的是在进行attention操作前, 通过通信算子使得每个进程拥有(B, L/N, ZxA) 转化到每个进程拥有(B, L, ZxA/N)的序列内容。attention 操作结束后, 再通过通信算子使得每个进程从拥有(B, L, ZxA/N)的序列内容转化为(B, L/N, ZXA)的序列内容。课件仅需要操作开始前, 结束后需要进行通信, attention的算子是完全独立的, 所以可以采用任意attention算子的实现。
Deepspeed ulyss的实现也非常简洁, 通过源代码就可以看到:
1 | # https://github.com/microsoft/DeepSpeed/blob/master/deepspeed/sequence/layer.py |
核心实现就是_SeqAllToAll这个函数的实现, 给定group, 在forward的时候通过通信将当前进程需要的序列聚积到当前进程, 在backward时, 我们通过后层收到的梯度也应该通过通信分发到正确的进程中, 并从别的进程中取到属于自己进程内容的梯度。以q, k, v的通信算子举例:
- forward时, 进程拥有(B, L/N, ZxA) 的序列内容, 通信后进程拥有(B, L, ZxA/N)
- backward时, 进程收到的梯度是(B, L, ZxA/N)内容的梯度, 但是本进程需要正确回传的梯度是(B, L/N, ZxA) 序列的梯度, 所以通过同样的算法得到正确的梯度
对于通信的算子, 最简单的算子就是AlltoAll, 使得每个进程在某个瞬间拥有(B, L, ZxA)的序列, 然后丢弃不需要的部分进行计算, 显然这样的方式会出现不必要的显存分配, 没有做到足够优雅的节省显存问题, 所以deepspeed使用的事AlltoAll_single这样的通信算子, 可以理解为将张量内容在进程间的某两个维度进行转置, 通信过程无需分配很多内容, 进一步提高效率。为了大家对AlltoAll_single有更好的理解, 这里附上pytorch对应算子的文档:
torch.distributed.all_to_all_single(output, input, output_split_sizes=None, input_split_sizes=None, group=None, async_op=False)
1 | input = torch.arange(4) + rank * 4 |
总结
本文介绍了序列并行解决的问题, 以及两种主流的实现序列并行的方式。其实两种序列并行可以混合使用, 从而达到更好的并行度和性能。同时在语言模型中, 带causal mask的情况下, 简单的序列切分会导致进程间计算负载不均衡, 随后衍生出striped attention。