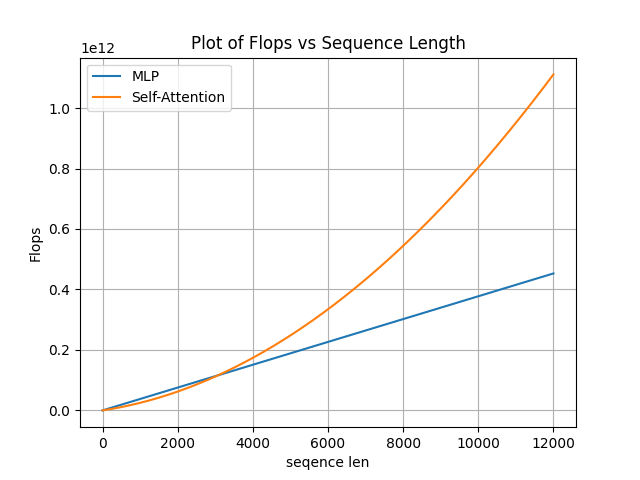
前言
Sora对于生成模型领域的impact, 远大于两年前的Dalle2, 因为Dalle2是将一个问题的性能提高一个层次, 从不可用变为可用。而Sora则是向世人展示一件事情是如何从不可能到可能的。其实从很多人的技术分析角度看, Sora背后的技术并不复杂, 我相信国内的公司也能够在一定的时间内复现出sora, 为什么说国内公司能复现, 因为他们已经看到了一件事情是可能的, 国内GPT百模大战的现象也是, 只有在OpenAI证明了一件事情是可行, 国内的公司才一窝蜂的上去做。
所以从这个角度看, 最顶尖的技术问题, 不是技术本身, 而是信念问题, 一种理性而坚定的信念。
而为什么OpenAI的团队能够有这样的信念呢, 如何在未知的情况下探索未知, 最后发现宝藏? 我想这一定和这群人有关系, 看清楚这群人有什么样的特质, 对未来个人发展规划, 技术公司寻找有潜力的创新人才, 总结美国在AI领域领先地位是如何形成的, 都有一定的益处, 所以这篇博客主要就是通过分析sora的作者们, 来看看有什么启发。
1. Tim Brooks
- Google Scholar
- 主页
- github
- linked In
- 博士: 2019.8-2023.1(共四年), PhD at Berkeley AI Research advised by Alyosha Efros
- 博士论文
- 学士: CMU, 2013-2017。
- 从博士年限上来看, 应该是读了硕士的, 但是硕士学历并没有写在领英中, 看起来应该是gap了,否则应该有早于2019年的文章 , 这或许是有意思的点。
- 从学士角度看, 应该在1994年出生。
在2019年就有两篇CVPR oral, 主要从事图相关处理(超分辨率, 在Google), 生成模型(GAN, 在NVIDIA)。明星工作是instrucPix2Pix, 这篇文章最大的亮点在于利用GPT3自动生成训练数据, 这样的思想在2022chatgpt出现以前是非常领先的。同时在随后从事了Dalle3和Sora的工作, 还参与了GPT4技术报告。可以说在OpenAI都负责到了比较核心的工作。
从推特看, 他自己也对自己Sora的工作非常满意, 疯狂转发Sora生成的视频。
从体来说, 他的求学生涯还是比较漫长的, 读了十年的书, 在本科和gap或者硕士阶段还没有很多的产出。从影响力来看, 博士生初期的作品也没有很显著, 但是他工作一个很重要的特点就是质量高(两篇oral), 其次就是他的工作紧密的和工业界, 特别是大厂结合; 出色的大厂经历, 并且在每一段大厂的经历中做出相关的工作, 而非只是给大厂打工, 我想这一点是需要很强motivation的。他起飞的阶段就是积极利用OpenAI的GPT资源, 同时有着先进的合成数据思想, 并付诸实践, 我觉得这样的思想也体现在了Sora的生成模拟器类似风格的视频的迹象中。
其实合成数据这个话题一直在被使用, 特别是在语言模型领域, 但是真正将其用在图像视频生成领域并把一个东西狠狠的调work, 都是不容易的。
其实对于一般的博士生而言, 只要数据不是开源的, 就立马被难住了, 自己也不愿意去复现数据的处理, 更别提自己取创造新的数据, 这些工作很脏, 但是却直接影响一些事情能不能开展, 我觉得放低自己的身位, 认真把工作做好这样的心态和毅力都是十分难得的。
2. Bill Peebles
所有的工作, 不是Oral就是Spotlight, 博士期间一共6篇工作, 其中一作仅两篇。主要专注于生成模型, 博士期间曾在FAIR, Adobe, NVIDIA实习。
Tim Brooks和Bill Peebles有多次合作, 其中有一篇比较有意思的是Learning to learn with generative models of neural network checkpoints, 利用生成模型生成神经网络的参数, 这可以理解为一种meta learning, 虽然这篇文章没有投稿和中稿, 但是背后的探索和尝试还是比较有意思的, 体现出了他们敢想敢做的精神。我觉得同样的, 丰富的大厂经历和资源, 扎实的工作, 敢想敢干, 这些都非常重要。
我觉得反观我自己, 有时候参与的事情过多, 为了自己忙而忙, 没有深刻思考自己研究的动机和意义, 有时候有想法却不敢大胆的做出来, 大胆的去想办法做, 没有尝试去大厂获取更多的资源, 这些我觉得和他们还是有重要的差距。
3. Connor Holmes
是Sora的system leader, 主要优化大规模训练和推理的, 看得出是做系统出身的, 曾在微软实习和工作, 主要参与DeepSpeed的相关工作。系统相关的作品非常多, 一年能有五六篇。做过图相关的高性能计算, RNN gpu优化, GPU并行DFS, Data efficient training of LLM。在高性能领域还是有功底的。
系统的优化对于模型的训练, 特别是成本的节约有非常重要的作用, 但是这决定的是成本和实现时间,这或许对于他刚进入openAI几个月之内就搞出Sora是他工作实力的证明。
4. Will DePue
注意, 这是一位大佬
当过九个月的CEO, 工程能力超强, 工程能力强在何处?
- FIGMA-OS 使用figma构建的8bit计算机
- WebGPT, 两个礼拜写完了, 获得了4k的github star
- Hyperlocal, 构建基于蓝牙的分布式点对点通信系统
- DeepResearch, 数据分析和可视化系统
- Built the first Redstone computer only using pistons. 第一个红石计算机, 有点猛。
在OpenAI 做过越狱和提示注入缓解、自定义模型、模型能力评估、API微调等工作, 这部分工作可能不是很和训练和设计相关, 确实也和工程很相关。
他说:
I find them restrictive: my most “hard skill” is that I am the fastest and most curious learner I’ve ever met.
学习能力很强, 学习速度很快, 这一切也体现在他的工程能力中。人也很想得开OpenAI让他退学就退学, 坚持做自己感兴趣的事情, 这样的人才的培养其实是很难得的, 我觉得我们或多或少都被一些大家都追求的东西裹挟, 比如GPA, 工资等等。这位兄弟排到了第四, 想必是做了相当多的工作。
5. Yufei Guo (郭宇飞)
主要做loss和优化相关的, 也做过一定的模型(尖峰神经网络)。这位同学22年还拿到过国家自然科学基金委的项目, 也有可能我理解有误, linkedIn的信息也非常有限, 这告诉我们要积极更新linkedIn给自己打广告呀。
6. Li Jing
在Meta做博后, 随后到OpenAI参与了Dalle3和Sora的工作。文章引用还是挺多的, 最有影响力的工作是和LeCun合作的Barlow twins: Self-supervised learning via redundancy reduction。因为是学物理的, 所以还用深度学习来进行粒子模拟和逆向设计, 发表在了Science advances上。我觉得他的物理功底和数学功底都是十分深厚的, 在Meta的工作也获得了比较大的影响力, 最后到OpenAI也是清理之中的, 但是无法从过去的工作中看出他在Sora中从事的工作和贡献。
7. David Schnurr
是一个典型的工程师, 在Graphiq, Uber做可视化平台, 主要技能是JS和Python, OpenAI的Node.js API引擎就是他写的。
8. Joe Taylor
看起来是设计学专业的, 从事过网页设计以及图像设计, 前端设计和开发。
Working on early research. Helping accelerate research, build product intuition and direction, building 0 -> 1 engineering systems. Announcement post;
其实不是很懂这句话是什么意思, 我觉得还是从产品, 设计以及宣传的角度去参与工作。
9. Troy Luhman
做了非常多diffusion 相关的工作, 主要关注高效生成和领域生成, 比较有意思的是文章只有两个作者, 合作者是下面的Eric Luhman, 我觉得可能是一家人。
10. Eric Luhman
主要和Troy Luhman合作, 做diffusion 领域相关的工作。
11. Clarence Ng
在AWS, google Cloud, Orach cloud都做过。
典型的工程师, 主要做云, 分布式系统和性能优化, 还做过对象存储, 可能对Sora的视频读取和处理进行了优化。工程经验极其丰富, 做的项目也很大, 是个优秀的人才。
12. Ricky Wang
主要也是工程师的画像, 在Instagram和Meta交替工作了非常多年。
13. Aditya Ramesh
是dalle和dalle2的作者, 还层参与GPT的工作, 学术功底深厚, 有14.5k的引用, 在OpenAI应该也算比较元老的任务, 所以是项目的总负责人。从这个视频看, 文字稿, 他还有点呆呆的。
总结
总sora的主要作者看, 我们可以从Sora团队学习到的经验是:
- 超前的认知, 注重scalable
- 大厂的经历和大厂的资源的支持, 做出出色的工作
- 极强的工程能力
- 良好可扩展的训练系统做支撑
- 好的数学功底和科研经验
- 参与过多种重大项目的leader的存在
我觉这一切还是值得自己反思的, 特别是大厂的经历和资源方面, 我觉得这是几乎所有人的共同特征。希望这篇博客与诸君共勉, 共同努力和进步。