Transformer-Performance
transformer 性能分析
简介
随着模型的不断变大, 模型的推理和训练成本在不断的提高, 如何更好的优化模型训练和推理的性能成为非常重要的领域, 10%的性能提升可能带来数十万乃至数百万成本的节省。
主要的性能优化一般来自于在计算逻辑不变的情况下对硬件更好的优化和利用, 或者在少量损失模型计算精度的情况下减少模型推理的计算量和放存量, 从而提高性能。
这篇博客主要学习这篇博客的分析思路, 先从内容的翻译和理解入手, 随后将博客的内容扩展到diffusion transformer以及训练相关的性能分析, 从而给如何优化以更好的理论指导。
约定和基础
在本博客中我们对数值的约定和参考的博客有一定的出入, 对于内存占用, 我们只计算元素的个数, 也就是不考虑每个参数的位宽, 只计算参数的个数。默认情况下
矩阵向量乘的计算量:
对于矩阵向量乘
kv cache解读
transformer在推理时分两个阶段,
- 是处理给定的prompt(是一次简单的forward, token一起喂入模型中)
- 随后是不断自回归地产生后续的token序列(每次只产生一个token)。这里需要提一点的是, transformer解码时之前所有计算的token对应的latent都和后续的token没有关系(因为attention mask的存在, 这也是为什么模型是autoregressive, 详情请见)。
因为之前的token和后面的token无关系, 所以这部分的值无需重复计算, 但是历史的K和V在每次计算中都需要(只被self attention 需要), 所以需要将每个transformer block的历史KV保存起来, 这部分保存的内容被称之为KV cache, 在使用KV cache的情况下, transformer每次只需要输入一个token用以计算, 无需输入再次前面的全部序列, 计算量是随着token个数线性增长。
对于每个token, 需要保存的KV cache参数量为:
其中(1+1)表示k和v。
对于计算一个新的token的KV cache, 我们需要的计算量为:
同时我们需要的访存量为:
总体而言, 是取参数的放存量占大头, token的访存量可忽略。
对于A100GPU而言, fp16的性能为312TFlops, 内存带宽为1.5T/s, 则用于计算一个token的KV访存耗时和计算耗时为:
可见, 用于访存的时间是用于计算的208倍之多, 这说明transformer解码的过程是内存瓶颈, 内存带宽。造成这种瓶颈的主要原因是解码时只计算一个token, 计算量小, 而模型的参数很大。
需要注意的是, KVcache的存在并不是仅仅为了节省计算KV本身所需要的计算量, 而是节省了前面所有token通过模型所需要的计算量。如果没有KVcache, transformer的解码过程会为平方级增长的计算量(第一次forward1个token, 第二次forward2个token, 第三次forward3token….), 这将难以承受。
💡 如果我们增大batch size, 能够获得在每次解码时更多的计算量和相近的访存量(因为主要放存量在模型权重), 而由于计算非常便宜, 我们的收益是大的(额外花1%的时间, 多获得一个token的解码), 这可能会提高每个token的延迟, 但是能够极大增加模型token的吞吐。对此已经有研究(ORCA)进行了优化, 使得模型吞吐上了一个量级, 造福了人类。
容量计算
接下来进行简单的容量计算分析, 对于一个52B(52e9 numel)的模型, 如果采用半精度存储, 则大约需要104GB(104e9 Bytes, two bytes for each parameter)的空间, 单卡无法放下, 同时在推理时KVcache 也需要占用空间。
给定4卡的A100 40G卡, 我们可以简单计算可以sample 的token数量。已知模型已经占了104G, 只有16G留给了KVcache。每个token需要的空间为:
模型并行
我们一般讨论的模型并行是指张量并行, 也就是将模型纵向切开, 每张卡上都有所有block参数的一部分。模型并行能够使得每张卡只承受一部分的模型参数存储和有一部分的计算量, 这些部分收到卡的数量的影响。模型并行会额外带来的开销是分块计算后同步计算结果的通信开销, 这部分会影响到推理的延迟。
此外, 将模型横向切分, 每张卡包含了若干个完整的block, 这样的方法被称为流水线并行, 由于每个token会依次通过所有block也就会依次通过每张卡一次, 每次只有一张GPU在进行计算, 所以每个token的延迟和单卡基本一致, 但是通过流水线的方法不断喂入token, 总的吞吐可以达到和4张卡一致。流水线并行唯一的好处在于需要的通信量比较小, 这适合卡间带宽比较小的场景。流水线并行需要在每张卡之间传递latent, 而张量并行需要每个block之间进行每张卡之间的通信, 通信量上一个量级。
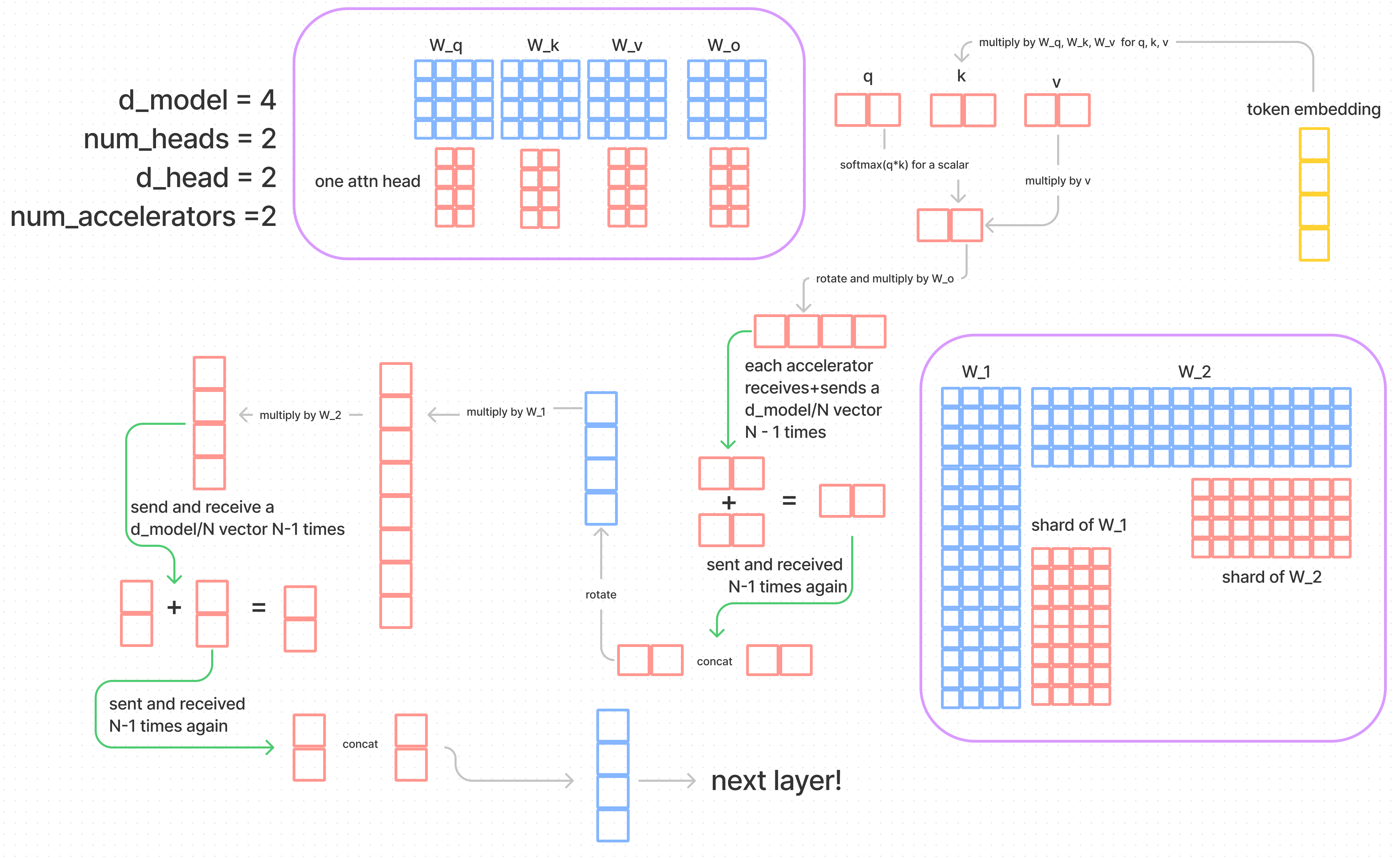
矩阵向量乘分块并行
考虑权重矩阵
分块后, 每个GPU的权重矩阵大小为
attention的并行
Attention的并行是通过在attention head的层面进行并行。head的切分维度刚好是在
各个模块计算量和访存量分析
标记:在diffusion transformer中, num_tokens = s = T * H * W
MLP
mlp的参数为
in_d,mid_d,out_d。通常情况而言,in_d=out_d,mid_d = 4 * in_dFlops=访存量:这里的访存量包括把结果写到内存中。
Vanilla self attention
- attention参数为:
in_d,mid_d,out_d。通常情况而言, 三者相等。 Flops=访存量:
Vanilla cross attention
- 参数为:
in_d,context_d,mid_d,out_d, 通常只有context_d 和其他三者不同 Flops=访存量:
Spatial self attention
- attention参数为:
in_d,mid_d,out_d。通常情况而言, 三者相等。 Flops=访存量:
Spatial cross attention
参数为:
in_d,context_d,mid_d,out_d, 通常只有context_d 和其他三者不同Flops=访存量:计算量和vanilla一致
temprol self attention
- attention参数为:
in_d,mid_d,out_d。通常情况而言, 三者相等。 Flops=访存量:
小讨论
可知MLP的计算量随着序列长度线性增长, 而sefl-Attention的计算量是平方级增长, 在这里我们可以计算一下经典场景下, 当序列长度到达什么水平时, Attention的计算量会成为主要部分。
in_d = mid_d = out_d, MLP mid_d=4in_d
则MLP的计算量公式为:
Attention计算量公式为:
在dim = 1536的情况下计算, 画图如下:
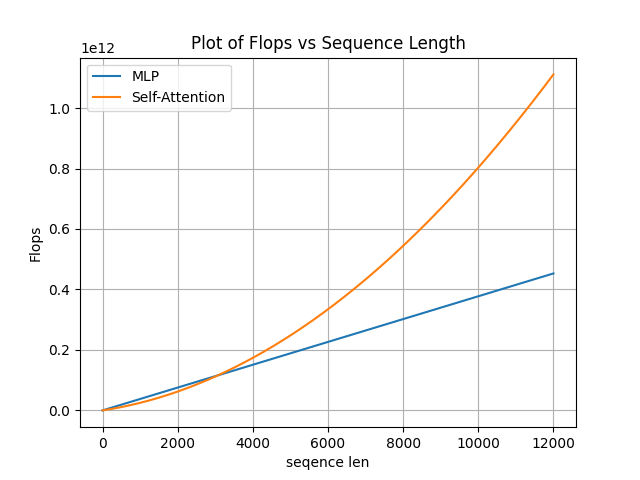
在大约3K以后, Attention的计算成为主要部分。
backward分析
考虑以下的三层MLP, x为输入,
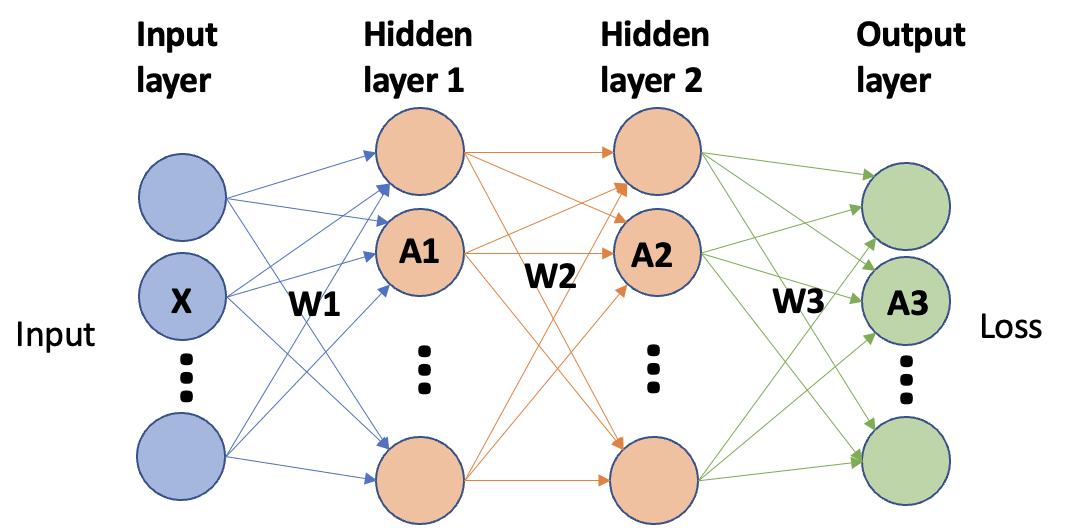
remark:
| Operation | Computation | mul shape | FLOP forward | Computation | FLOP backward | mul shape |
|---|---|---|---|---|---|---|
| Input | ||||||
| ReLU | ||||||
| Derivative | ||||||
| Hidden1 | ||||||
| ReLU | ||||||
| Derivative | ||||||
| Hidden2 | ||||||
| ReLU | ||||||
| Loss | ||||||
| Update |
注意到, 因为input x 无需计算梯度, 所以对于第一层而言, backward节省了约一半的计算量。所以在网络较深的情况下, backward的计算时间约为forward计算时间的两倍。
参考资料
Transformer-Performance

